摘要
通过两个开源项目,对AI绘画与虚拟主播技术进行尝试,了解其背后技术,总结学习记录并对技术融合落地进行探讨。
技术介绍
AI绘画使用的是 stable-diffusion-webui开源项目
操作系统win10
显卡:NVIDIA 1050ti 4G
python:3.10.6
该项目目前还在持续更新中
AI绘画突然火爆主要是一篇论文的出现,即人工智能的扩散算法。(所以这些AI绘图产品名字里都带个diffusion)所谓扩散算法,是指先将一幅画面逐步加入噪点,一直到整个画面都变成白噪声。记录这个过程,然后逆转过来给AI学习。AI那里看到的是一个全是噪点的画面是如何一点点变清晰直到变成一幅画的,AI通过学习这个逐步去噪点的过程来学会作画。这个算法出来之后效果非常好,比以前的AI绘画效果要好的多。
虚拟主播使用的是PaddleBoBo开源项目
操作系统win10
显卡:NVIDIA 1050ti 4G
python:3.7.2
该项目更近似于一个demo,但对虚拟主播生成也可见一斑。
PaddleBoBo主要集成了PaddleGAN和PaddleSpeech的超能力,目前具体集成的是PaddleGAN的FOM、Wav2Lip模块和PaddleSpeech的TTS模块。
技术实现原理如下:
首先,把图像放入FOM进行面部表情迁移,让虚拟主播的表情更加逼近真人,既然定位是一个主播,那表情都参考当然是要用“国家级标准”的,所以BoBo参考的对象是梓萌老师。
同时,通过PaddleSpeech的TTS模块,将输入的文字转换成音频输出。
得到面部表情迁移的视频和音频之后,通过Wav2Lip模块,将音频和视频合并,并根据音频内容调整唇形,使得虚拟人更加接近真人效果。
操作流程及结果
关于项目搭建没什么好说的,主要是运行环境的配置。国内还是受限于网络环境。
stable-diffusion-webui
简单生成一张图片:

参数(丹方)
(8k, RAW photo, best quality, masterpiece:1.2), (realistic, photo-realistic:1.37),<lora:koreanDollLikeness_v10:0.5>, omertosa,1lady, (aegyo sal:1),city, ,professional lighting, photon mapping, radiosity, physically-based rendering, blue backlight bokeh, smile, mature, head portrait,sunlight>,blone,short jacket,school uniform,hoodie,short hair, floating hair,only head,front
Negative prompt: EasyNegative, paintings, sketches, (worst quality:2), (low quality:2), (normal quality:2), lowres, normal quality, ((monochrome)), ((grayscale)), skin spots, acnes, skin blemishes, age spot, glans,extra fingers,fewer fingers,strange fingers, bad hand, high heel shoes, fat ass, hole,kid,teen,cute,naked, Ripped jeans, hole jeans, fat thigh,6 fingers, bikini, underwear, nsfw, nude, briefs, knickers, underpants, panties, swim suit,leg open
Steps: 20, Sampler: DPM++ 2M Karras, CFG scale: 5, Seed: 3534095324, Size: 512x512, Model hash: fc2511737a, Model: chilloutmix_NiPrunedFp32Fix, Clip skip: 2
说一下问题,ai绘画确实存在绘画手部的问题,但这更像是绘画长条状物体的问题,不单单局限于绘画手部。不过有大佬通过调参似乎可以绘画出好看的手,这个问题似乎也不是很大。
此外由此引发的法律与道德的问题,这里不做讨论。
PaddleBoBo
PaddleBoBo是基于飞桨PaddlePaddle深度学习框架和PaddleSpeech、PaddleGAN等开发套件的虚拟主播快速生成项目。PaddleBoBo致力于简单高效、可复用性强,只需要一张带人像的图片和一段文字,就能快速生成一个虚拟主播的视频;并能通过简单的二次开发更改文字输入,实现视频实时生成和实时直播功能。
本地搭建好环境以后,准备一张含有人脸的静态图片,和一个用作表情迁移的参考视频:

分别执行指令生产视频。
尝试
那么如果我使用stable-diffusion-webui生成静态人像,再使用PaddleBoBo生成虚拟主播会如何呢?
可以看出该视频的唇部存在一些问题,而且仅仅头部可以移动。虽然如此,但经过二次开发,应该是有落地的可能性。
总结与展望
本文并不是一篇探讨技术的文章,所以只是略提一下,更多的是想讨论一下AI技术的落地场景。
目前,已经有多种AI绘画的项目,同时虚拟主播也发展良好而且后者已经形成生态,且有落地应用。
这里提一下ChatGpt人工智能技术驱动的自然语言处理工具,于2022年11月30日发布。其基于2020年发布的gpt3,通过训练,形成gpt3.5版本也就是现在的ChatGpt。
笔者通过搭建gpt3的服务,并将其接入微信公众号中:
不难看出gpt3还存在胡言乱语的现象。
但ChatGpt却较之有巨大进步,无论是对话还是对于问题的解决,都可以展示出非凡的能力。
那么我们上面的尝试如果将ChatGpt也引入呢?是不是可以使用ChatGpt写一段文稿,再交由虚拟主播进行播报,这有助于新闻类短视频快速生产,且有效降低生产成本。
国内剪辑软件剪映现在已经支持图文生成视频,我们完全可以利用ChatGpt生成一段影评,交由相关软件进行视频制作,笔者测试,唯一的的问题是素材来源良莠不齐。未来应该可以从指定的素材中进行剪辑。那么以后的资讯类制作是否也可以从中获取一定帮助呢?由AI分析视频与文稿再生产新的视频,交由人工进行二次剪辑,在生产流程上必将有巨大提升。
另外在录制视频需要使用提词器的时候,总会发生阅读人目光无法聚集于摄像头,导致目光飘忽不定,NVIDIA似乎已经提出解决方案,笔者测试后发现效果良好,虽然其还在开发当中。
似乎现在唯一的限制就是硬件!
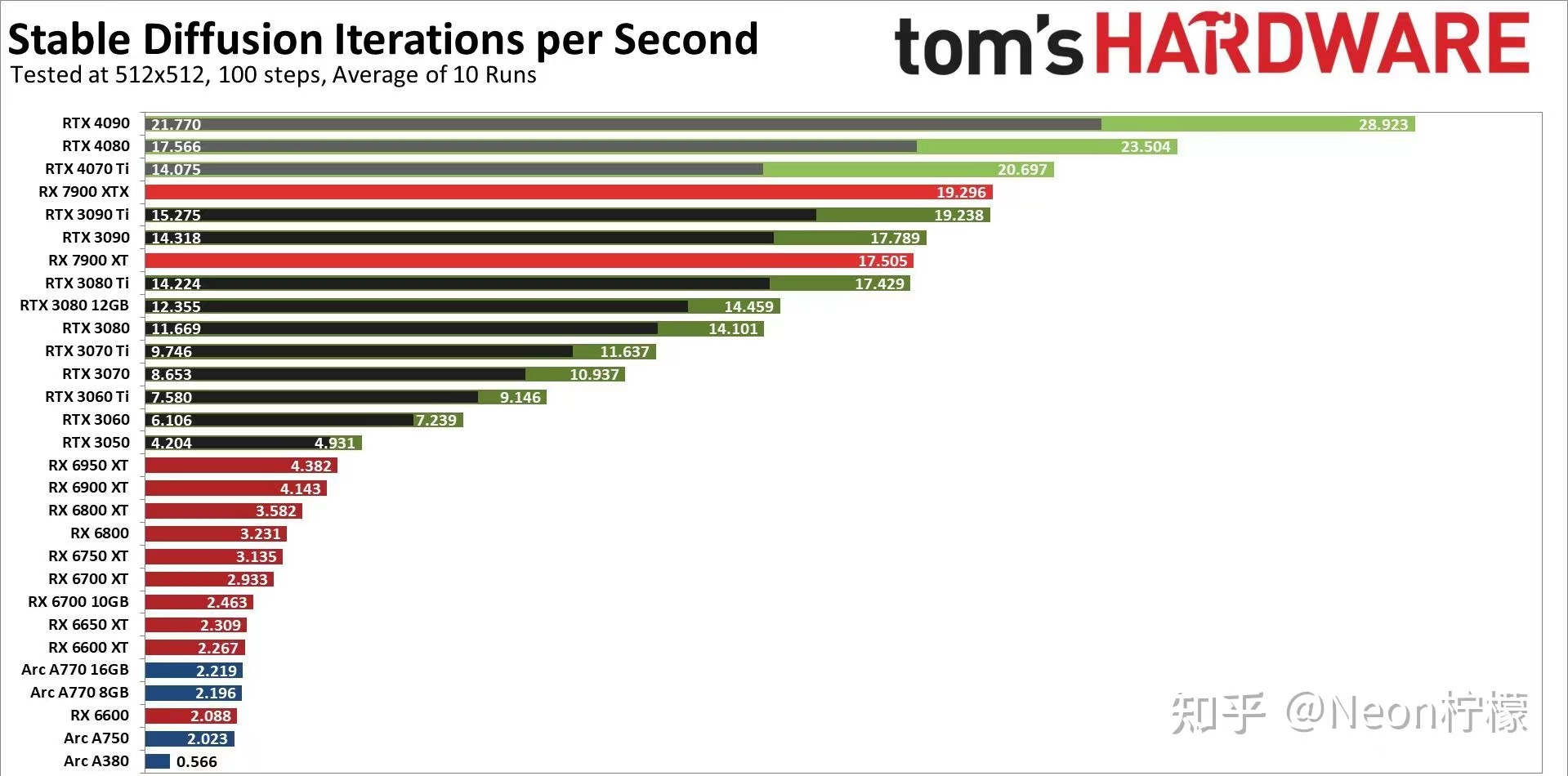
从上图可以看出,显卡对于生产的关键性。
但是人呢?会被替代吗?
AI终究是工具,在搭建PaddleBoBo过程中,笔者曾多次求助于ChatGpt,可谓受益良多。可以这样说,AI会使弱者变强,会使强者越强,关键在于使用的方式。
但是一些简单重复的工作终究是会被替代,绘画行业如此需要创意的行业已经受到冲击,更遑论其他简单行业。传统媒体的制作是否会受到冲击,似乎不言而喻。但是,同时也诞生了一个行业:调参师。我们能做的只有接受。
写到这里我似乎该卖课了。。。。。
但笔者还在探索中,如果说科技是第一生产力,那么牛子就是第一探索力。笔者还在学习探索当中,这也就是这篇文章不讨论技术的原因,我还没有能力,只是想分享记录一下目前的学习成果。
祝各位身体健康。学道无阻。
鸣谢:
非常感谢两位孙老师对于设备,技术和思路的大力支持。