介绍
项目地址:THUDM/ChatGLM-6B: ChatGLM-6B:开源双语对话语言模型 | An Open Bilingual Dialogue Language Model (github.com)
官方介绍:
ChatGLM-6B 是一个开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。 ChatGLM-6B 使用了和 ChatGPT 相似的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 已经能生成相当符合人类偏好的回答,更多信息请参考我们的博客。
为了方便下游开发者针对自己的应用场景定制模型,我们同时实现了基于 P-Tuning v2 的高效参数微调方法 (使用指南) ,INT4 量化级别下最低只需 7GB 显存即可启动微调。
不过,由于 ChatGLM-6B 的规模较小,目前已知其具有相当多的局限性,如事实性/数学逻辑错误,可能生成有害/有偏见内容,较弱的上下文能力,自我认知混乱,以及对英文指示生成与中文指示完全矛盾的内容。请大家在使用前了解这些问题,以免产生误解。更大的基于 1300 亿参数 GLM-130B 的 ChatGLM 正在内测开发中。
测试介绍:
本地采用秋叶的一键包,参考官方案例,通过调用Api的方式,使用ChatGLM-6B。
环境介绍
Win10 16G
Nvidia 3050 8G
秋叶ChatGLM-6B一键包
过程:
一、 修改部分代码
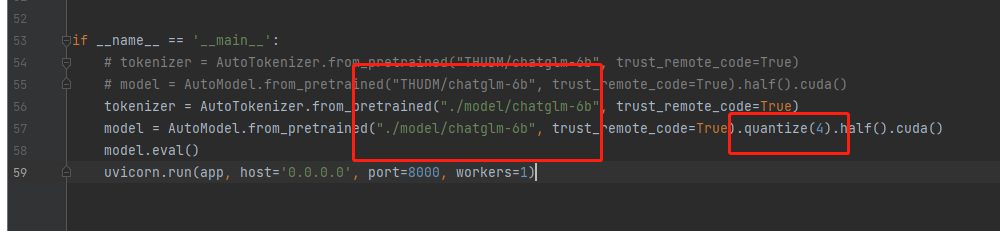
秋叶的包缺少部分文件,需要自行下载Api.py文件,同时修改部分代码,参考下图:修改了model的位置,本地显存不够,需要多加一个.quantize(4),以量化方式加载模型。
二、 执行
写了一个.bat文件,指定一下python路径,和模型路径。
等待项目启动,使用curl发送post命令

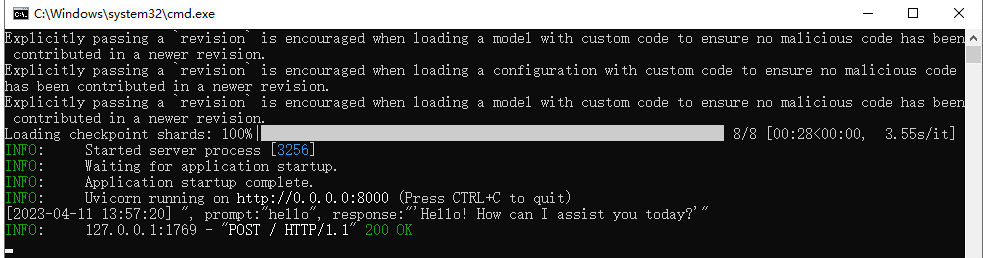

curl -i -X POST -H "Content-Type:application/json" -d "{\"prompt\": \"hello\", \"history\": [] }" http://127.0.0.1:8000
总结
本次是在win10环境下,在cmd中采用curl发送post命令,因为编码的 原因需要对一些符号需要进行转义。ChatGLM-6B对中文支持很好,如果需要发送中文,可以尝试一下这种方法,但是未经测试。

iconv -f utf-8 -t gbk
如果想自己训练的话,推荐显存12G以上,虽然可以通过量化方式,降低对显存的需求,但是效果应该不会太好。显存不足,多次调试均会爆显存,遂放弃。
ChatGLM-6B体量还是太小,上下文对话效果不错,但是也会出现胡言乱语的情况,而且对显存有一定要求,常常对话两三轮就会爆掉。
还是很牛*的,最起码比体验不到的文心一言感觉要好。